Der Ursprung der Sprache des Lebens
| 19. Dezember 2014
ERC Starting Grant Preisträger Bojan Žagrović und seine KollegInnen an den Max F. Perutz Laboratories sind dem genetischen Code auf der Spur (Foto: privat).
Das Leben kennt nur eine Sprache: den genetischen Code. Wie dieser entstanden ist, ist noch ein Rätsel. Wichtige Hinweise zur Lösung hat das Forschungsteam von Bojan Žagrović an den Max F. Perutz Laboratories (MFPL) der Universität Wien und der Medizinischen Universität Wien geliefert.
In den Genen ist die gesamte Information über ein Lebewesen gespeichert. Sie enthalten z.B. den Code für unsere Größe und Augenfarbe, aber auch für bestimmte Krankheitsanlagen. Damit Zellen die in den Genen gespeicherten Informationen lesen können, wird von diesen zuerst eine Abschrift in Form sogenannter Messenger – also Boten-RNAs (mRNAs) – gemacht. Deren Botschaft wird in einem zweiten Schritt gelesen und zur Herstellung von Proteinen, den Arbeitstieren der Zelle, verwendet.
Während die Informationen der mRNAs in einem 4-Buchstaben-Alphabet von Nukleobasen geschrieben stehen, bestehen Proteine aus einem 20-Buchstaben-Alphabet von Aminosäuren. Der genetische Code ist der Schlüssel zur Übersetzung der Sprache der mRNAs in die Sprache der Proteine, und wurde bereits vor mehr als 50 Jahren von WissenschafterInnen geknackt. Obwohl wir die Wörter aus Nukleobasen lesen und verstehen können – also wissen, für welche Aminosäure sie stehen – ist der Ursprung dieser universellen Sprache des Lebens weiterhin ein Mysterium.
Codierung durch Bindung
Eine Theorie zur Entstehung des genetischen Codes ist die sogenannte stereochemische Hypothese. Diese geht davon aus, dass der genetische Code eine Folge der direkten Bindungsneigung von Aminosäuren für die entsprechenden Nukleobasen ist. Dieser Theorie zufolge hätten, vereinfacht gesagt, die Symbole des genetischen Codes (Nukleobasen) eine direkte Neigung, die Objekte zu binden für die sie stehen (Aminosäuren). Da diese Bindungsneigungen jedoch vergleichsweise schwach zu sein scheinen, gab es bisher kaum überzeugende experimentelle Beweise für die stereochemische Hypothese.
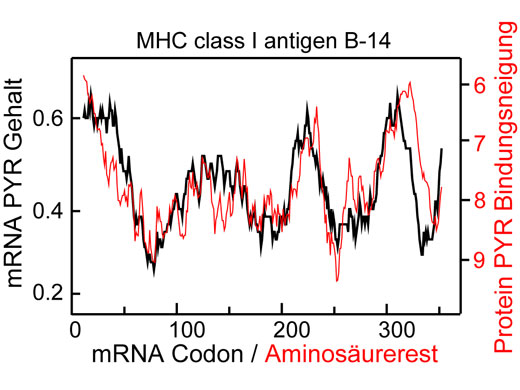
Andererseits erhielte man möglicherweise aufschlussreichere Signale, wenn man sich vollständige mRNAs und die von ihnen codierten Proteine anschaut – eine Möglichkeit, der ERC Starting Grant Preisträger Bojan Žagrović und seine KollegInnen an den Max F. Perutz Laboratories (MFPL) der Universität Wien nachgingen. In den letzten beiden Jahren haben Žagrović und sein Team Beweise gesammelt, die darauf hindeuten, dass die meisten mRNAs moderner Lebewesen Signaturen enthalten, die auf eine mögliche komplementäre Wechselwirkung mit den Proteinen hindeuten, für die sie codieren. Die WissenschafterInnen untersuchten diese Beziehung in kompletten Proteomen – also die Gesamtheit der Proteine von Zellen – für 15 verschiedene Organismen aus allen drei Domänen der Lebewesen.
Komplementäre Wechselwirkungen
Mithilfe experimenteller sowie rechnerisch abgeleiteter Daten konnte das Team zeigen, dass die Dichteprofile verschiedener Nukleobasen in mRNAs den Profilen der Aminosäureaffinität für dieselben Nukleobasen im zugehörigen codierten Protein ähneln. Zusätzlich konnten die ForscherInnen nachweisen, dass der genetische Code hinsichtlich dieser Matchings sogar stark optimiert ist. Diese Ergebnisse sind nicht nur wichtig, weil sie darauf hindeuten, dass der genetische Code tatsächlich als Folge der direkten Bindungswechselwirkungen zwischen mRNAs und Proteinen entstanden ist, sondern zudem bedeuten, dass derartige Wechselwirkungen auch in heutigen Organismen von Bedeutung sein könnten. Letzteres würde eine neue, bisher unbekannte Ebene der Genregulation darstellen.
|
|
|---|
Ähnlich einem Keksausstecher?
"Man kann unsere Ergebnisse mit folgender Analogie erklären: Schickt man Freunden ein Rezept für Weihnachtsplätzchen, die die Form eines Christbaums haben sollen, und erklärt ihnen nun schriftlich die Form des Baumes, würde kein Baum gleich aussehen. Würde man dem Rezept jedoch einen Keksausstecher in Form eines Christbaumes beilegen, würden alle Bäume genau gleich aussehen, da die Information über die Form des Baumes detailgetreu in der Form des Keksausstechers 'codiert' ist. Unsere Ergebnisse legen nahe, dass der genetische Code am Anfang vielleicht viel simpler war und Informationen für Proteinsequenzen in den physiko-chemischen Eigenschaften der komplementären mRNA Sequenz gespeichert waren", erklärt Bojan Žagrović.
|
|
|---|

Hallen Echos von Urereignissen auch heutzutage nach?
Während drei der vier mRNA-Nukleobasen eine direkte Präferenz für die Aminosäuren zeigten, für die sie codieren, fanden die WissenschafterInnen heraus, dass sich Adenin genau umgekehrt verhält. Sie vermuten, dass das darauf hindeutet, dass Adenin erst in einer zweiten Entwicklungsphase des genetischen Codes entstanden ist, und dazu dient, Bindungen zu modulieren und zu schwächen.
"Der nächstliegende Prozess, bei dem mRNA und Protein in einer Zelle in unmittelbarer Nähe vorkommen, ist die Translation. Ein neu gebildetes Protein könnte zum Beispiel die Translation seiner eigenen mRNA unterdrücken, indem es mit der Proteinsynthese-Maschinerie um die mRNA-Bindung konkurriert", sagt Bojan Žagrović. "Wir forschen weiter und sind sehr gespannt, ob die Ergebnisse tatsächlich auch in heutigen zellulären Regulationsprozessen eine Rolle spielen. Es wäre wirklich hochinteressant, wenn die Echos von Urereignissen der Entstehung des Lebens heute noch nachhallen würden", resümiert der Molekularbiologe. (red)
Die Publikation "Proteome-wide analysis reveals clues of complementary interactions between mRNAs and their cognate proteins as the physicochemical foundation of the genetic code" (AutorInnen: Anton A Polyansky, Mario Hlevnjak and Bojan Zagrovic) erschien im August 2013 in "RNA Biology".
Die Publikation "Computational analysis of amino acids and their sidechain analogs in crowded solutions of RNA nucleobases with implications for the mRNA–protein complementarity hypothesis" (AutorInnen: Matea Hajnic, Juan Iregui Osorio and Bojan Zagrovic) erschien im Dezember 2014 in "Nucleic Acids Research".


